Quantum-centric workflows need an operating layer, not another notebook
IBM's 2026 reference architecture puts orchestration, shared storage, and coordinated quantum-classical work at the center of practical adoption.
8 chapters
24 source notes
7 sources
primary links
3 signals
operating context
3,740 words
reviewed analysis
Quantum teams are moving from isolated circuit experiments toward coordinated workflows that blend QPUs, CPUs, GPUs, queues, learning, logs, and evidence. The product implication is clear: the interface should show route, execution, and review context as one operating record.


152,064
classical nodes
closed-loop exchange in a published IBM/RIKEN workflow
Q1 2026
Qiskit logs
real-time logs surfaced for Qiskit Functions
1 record
workflow packet
design, route, run, and proof stay connected
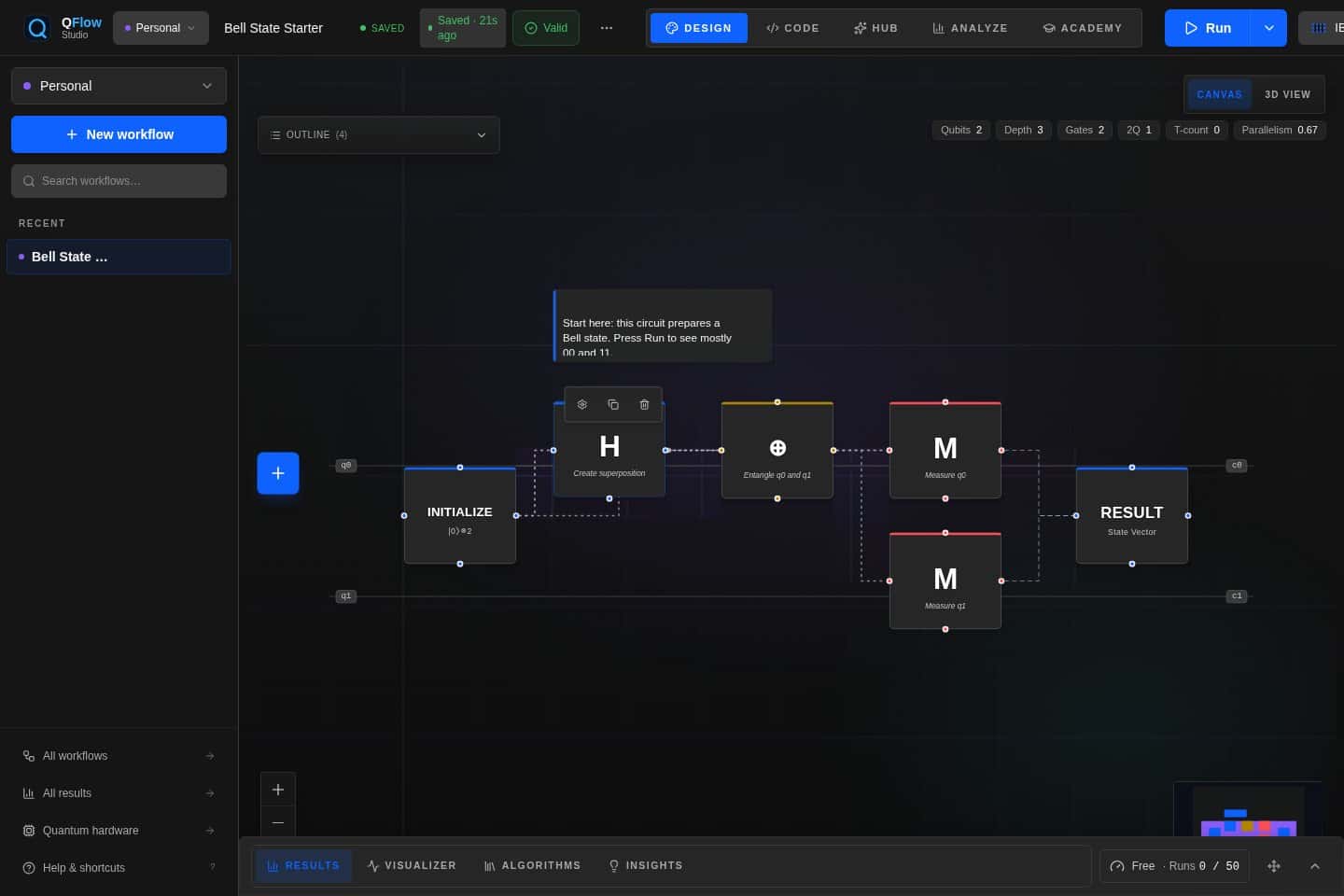
The practical unit is the workflow
The 2026 pattern is less about a single circuit screenshot and more about a linked chain of intent, compiled circuit, selected backend, execution logs, artifacts, and review proof. Teams need to see the state of that chain without assembling it manually across notebooks and provider portals.
Control planes must stay readable
A serious dashboard should not expose every subsystem at once. QFlow Studio should lead with the active workflow, then reveal route, code, run, and evidence panels through progressive controls that fit laptop and mobile screens.
Evidence is part of operations
Qiskit Functions adding real-time logs reinforces a bigger point: execution visibility belongs beside the circuit, not in a separate after-action report. Teams should be able to explain what ran, where it ran, and which artifacts are safe to share.
Design implication for QFlow
The product should treat the run as a live record instead of a terminal event. A designer should see the research brief, circuit state, route rationale, execution status, and evidence packet as one object that can be reviewed and replayed.
That means the interface needs calm hierarchy. The active workflow gets the large surface, while provider state, logs, exports, and reviewer artifacts stay close enough to inspect without turning the page into a monitoring wall.
What teams should inspect next
A serious pilot review should ask whether the workflow can survive repetition. Can a second researcher reproduce the route? Can an admin understand who owns provider access? Can a reviewer see counts and trace without receiving credentials or unrelated workspace data?
Those questions are product questions as much as research questions. The best operating layer makes the answers visible before the team spends another hardware run.
Why notebooks are not enough anymore
Notebooks are excellent for exploration, but a quantum-centric workflow needs more than a cell history. It needs an operating record that captures source intent, circuit version, route decision, provider state, queue context, code export, run evidence, and review boundary. When those items live in separate tabs, a team can produce interesting experiments without producing a durable process.
The practical problem appears during review. A sponsor asks what changed between simulation and hardware. A security lead asks whether credentials were shared. A second researcher asks how to reproduce the run. A notebook can answer some of those questions, but it rarely answers all of them in one place.

QPU, GPU, and CPU work should be one timeline
IBM's reference architecture and NVIDIA's CUDA-Q positioning both point toward hybrid execution as the default. The QPU is not replacing classical infrastructure; it is being orchestrated with CPUs, GPUs, storage, schedulers, simulators, and domain software.
QFlow should therefore show the workflow timeline, not just the circuit. The user should be able to see when a run was modeled, compiled, simulated, routed, executed, compared, and packaged. That timeline is the product surface that turns quantum-centric supercomputing into something a team can operate.
Review packets are the bridge to adoption
A research team may be satisfied with a successful run, but an enterprise team needs a shareable packet. That packet should include the objective, circuit snapshot, generated code, provider path, run status, counts, trace, export format, and private-boundary statement.
This is where QFlow can be opinionated. The product should make the packet automatic enough that teams do not build slides by hand, but structured enough that reviewers can trust what they are seeing.
Source signal 1: IBM Newsroom
This IBM Newsroom source is included because it gives this article a concrete 2026-03-12 evidence point instead of a loose market claim. For a reader searching Quantum-centric supercomputing, Qiskit, HPC, the useful move is to ask what this source changes in practice: current access, roadmap confidence, route fit, run evidence, learning scope, or procurement risk. The evidence question is whether the source changes route choice, run mode, queue planning, fallback behavior, or the artifact packet a reviewer receives.
QFlow should turn that signal into a visible workflow step: source assumption, provider path, expected output, fallback path, and final decision state. The article should therefore treat IBM Newsroom as an input to an operating decision, not as decorative citation text. A team can copy the source into a workflow brief, attach the exact claim being tested, and decide whether the next step is simulation, hardware execution, resource estimation, provider comparison, or reviewer preparation.
The reviewer should see what was tested, what changed because of the source, and which private operations remained outside the share packet. That keeps the source trail useful months later. If IBM Newsroom updates the page, releases a new benchmark, changes access rules, or supersedes the claim, the affected workflow has a clear place to be reviewed rather than becoming stale background reading.
Source signal 2: IBM Quantum Blog
This IBM Quantum Blog source is included because it gives this article a concrete Q1 2026 evidence point instead of a loose market claim. For a reader searching Quantum-centric supercomputing, Qiskit, HPC, the useful move is to ask what this source changes in practice: current access, roadmap confidence, route fit, run evidence, learning scope, or procurement risk. The evidence question is whether the source changes route choice, run mode, queue planning, fallback behavior, or the artifact packet a reviewer receives.
QFlow should turn that signal into a visible workflow step: source assumption, provider path, expected output, fallback path, and final decision state. The article should therefore treat IBM Quantum Blog as an input to an operating decision, not as decorative citation text. A team can copy the source into a workflow brief, attach the exact claim being tested, and decide whether the next step is simulation, hardware execution, resource estimation, provider comparison, or reviewer preparation.
The reviewer should see what was tested, what changed because of the source, and which private operations remained outside the share packet. That keeps the source trail useful months later. If IBM Quantum Blog updates the page, releases a new benchmark, changes access rules, or supersedes the claim, the affected workflow has a clear place to be reviewed rather than becoming stale background reading.
Source signal 3: IBM Quantum
This IBM Quantum source is included because it gives this article a concrete 2026 product page evidence point instead of a loose market claim. For a reader searching Quantum-centric supercomputing, Qiskit, HPC, the useful move is to ask what this source changes in practice: current access, roadmap confidence, route fit, run evidence, learning scope, or procurement risk. The evidence question is whether the source changes route choice, run mode, queue planning, fallback behavior, or the artifact packet a reviewer receives.
QFlow should turn that signal into a visible workflow step: source assumption, provider path, expected output, fallback path, and final decision state. The article should therefore treat IBM Quantum as an input to an operating decision, not as decorative citation text. A team can copy the source into a workflow brief, attach the exact claim being tested, and decide whether the next step is simulation, hardware execution, resource estimation, provider comparison, or reviewer preparation.
The reviewer should see what was tested, what changed because of the source, and which private operations remained outside the share packet. That keeps the source trail useful months later. If IBM Quantum updates the page, releases a new benchmark, changes access rules, or supersedes the claim, the affected workflow has a clear place to be reviewed rather than becoming stale background reading.
Source signal 4: NVIDIA Developer
This NVIDIA Developer source is included because it gives this article a concrete 2026 product page evidence point instead of a loose market claim. For a reader searching Quantum-centric supercomputing, Qiskit, HPC, the useful move is to ask what this source changes in practice: current access, roadmap confidence, route fit, run evidence, learning scope, or procurement risk. The evidence question is whether the source changes route choice, run mode, queue planning, fallback behavior, or the artifact packet a reviewer receives.
QFlow should turn that signal into a visible workflow step: source assumption, provider path, expected output, fallback path, and final decision state. The article should therefore treat NVIDIA Developer as an input to an operating decision, not as decorative citation text. A team can copy the source into a workflow brief, attach the exact claim being tested, and decide whether the next step is simulation, hardware execution, resource estimation, provider comparison, or reviewer preparation.
The reviewer should see what was tested, what changed because of the source, and which private operations remained outside the share packet. That keeps the source trail useful months later. If NVIDIA Developer updates the page, releases a new benchmark, changes access rules, or supersedes the claim, the affected workflow has a clear place to be reviewed rather than becoming stale background reading.

Source signal 5: IBM Technology Atlas
This IBM Technology Atlas source is included because it gives this article a concrete 2026 roadmap evidence point instead of a loose market claim. For a reader searching Quantum-centric supercomputing, Qiskit, HPC, the useful move is to ask what this source changes in practice: current access, roadmap confidence, route fit, run evidence, learning scope, or procurement risk. The evidence question is whether the source changes route choice, run mode, queue planning, fallback behavior, or the artifact packet a reviewer receives.
QFlow should turn that signal into a visible workflow step: source assumption, provider path, expected output, fallback path, and final decision state. The article should therefore treat IBM Technology Atlas as an input to an operating decision, not as decorative citation text. A team can copy the source into a workflow brief, attach the exact claim being tested, and decide whether the next step is simulation, hardware execution, resource estimation, provider comparison, or reviewer preparation.
The reviewer should see what was tested, what changed because of the source, and which private operations remained outside the share packet. That keeps the source trail useful months later. If IBM Technology Atlas updates the page, releases a new benchmark, changes access rules, or supersedes the claim, the affected workflow has a clear place to be reviewed rather than becoming stale background reading.
Source signal 6: AWS Documentation
This AWS Documentation source is included because it gives this article a concrete 2026 documentation evidence point instead of a loose market claim. For a reader searching Quantum-centric supercomputing, Qiskit, HPC, the useful move is to ask what this source changes in practice: current access, roadmap confidence, route fit, run evidence, learning scope, or procurement risk. The evidence question is whether the source changes route choice, run mode, queue planning, fallback behavior, or the artifact packet a reviewer receives.
QFlow should turn that signal into a visible workflow step: source assumption, provider path, expected output, fallback path, and final decision state. The article should therefore treat AWS Documentation as an input to an operating decision, not as decorative citation text. A team can copy the source into a workflow brief, attach the exact claim being tested, and decide whether the next step is simulation, hardware execution, resource estimation, provider comparison, or reviewer preparation.
The reviewer should see what was tested, what changed because of the source, and which private operations remained outside the share packet. That keeps the source trail useful months later. If AWS Documentation updates the page, releases a new benchmark, changes access rules, or supersedes the claim, the affected workflow has a clear place to be reviewed rather than becoming stale background reading.
Decision model for a 2026 reader
A reader should leave this article with a decision model, not just a longer list of names and numbers. The first decision is whether the topic changes something the team can do this quarter. The second is whether the claim depends on current access, future roadmap delivery, a simulated estimate, or a vendor-controlled benchmark. The third is whether the team has enough evidence to brief a sponsor without overstating the result.
For Quantum-centric workflows need an operating layer, not another notebook, the working model starts with 152,064 classical nodes. That signal should be translated into an operating question: what would we run, where would we run it, what fallback path would be acceptable, and what artifact would prove progress? QFlow should make those questions visible beside the workflow so the article can become a repeatable pilot plan.
What stronger blog detail should preserve
Adding more article depth should not mean adding filler. The detail that matters is the connective tissue between source, implication, workflow, and review. A strong section explains what the source says, which assumption it changes, how a team would test the assumption, and what evidence would survive handoff to another reader.
That structure is especially important in 2026 because quantum announcements are moving quickly and use different confidence levels. Product pages describe access, roadmaps describe intent, research papers describe controlled experiments, and market reports describe commercial momentum. The blog needs to keep those categories separate while still giving the reader one practical path forward.
Where the article becomes product behavior
The article becomes product behavior when 1 record workflow packet is attached to a concrete workflow state. In QFlow, that should look like a source brief, a route note, a run mode, a fallback branch, an artifact checklist, and a reviewer-safe summary. The public page explains why the workflow exists; the studio preserves what the team did with it.
That connection also improves maintenance. If a source changes, the article, template, learning content, and review packet can be updated together. The product does not need a separate content strategy and operations strategy. It needs one source-to-workflow model that keeps 2026 research, provider updates, and market signals tied to decisions users can inspect.
Direct answer for 2026 search intent
Quantum-centric workflows need an operating layer, not another notebook answers a practical 2026 search question: how should a serious team interpret Quantum-centric supercomputing, Qiskit, HPC without confusing roadmap momentum with deployable operating capability. The short answer is to connect every claim to a workflow decision. If the claim changes provider choice, run mode, evidence requirements, learning scope, or procurement risk, it belongs in the operating record. If it does not change a decision, it should remain background context.
That answer matters because quantum searches in 2026 are full of mixed signals. Some pages describe current cloud access, some describe early fault-tolerant roadmaps, some describe research proofs, and some describe public-market momentum. The useful article separates those signals and tells the reader what to do next. For this topic, the next action is to turn the research into a narrow pilot packet with objective, route, fallback, artifact list, reviewer, and decision date.
This is also why the article favors sources over slogans. A reader should leave with the exact claims to inspect, the sources behind them, and the product surface where those claims become work. That is the standard QFlow should keep for every blog post: helpful, current, sourced, and directly connected to the studio.

Operational readout for product teams
Quantum-centric workflows need an operating layer, not another notebook should be read as an operating brief, not as a detached market note. The practical question is how a team would use this signal inside a live workflow: what changes in route selection, what evidence must be captured, which users need to see the result, and which private details must stay inside the workspace.
The useful product response is to keep the article close to the studio model. A team should be able to move from the source material into a workflow packet that records objective, owner, circuit or model state, provider path, execution mode, artifacts, and review notes. That packet is where strategy becomes operational memory.
This also changes how the blog should be maintained. Each article needs enough context for an executive reader to understand why the signal matters, enough implementation detail for a technical lead to frame a pilot, and enough source discipline for a reviewer to separate current capability from roadmap promise. Long-form content is valuable only when it reduces handoff loss between those readers, and when it leaves a clear path from reading to product action for the next review cycle. For this article, the operational lens is workflow routing, run evidence, reviewer packets, and source-to-action continuity.
Source-by-source interpretation
The source trail for this article starts with IBM Newsroom (2026-03-12), IBM Quantum Blog (Q1 2026), IBM Quantum (2026 product page), NVIDIA Developer (2026 product page). That matters because current quantum content often mixes vendor roadmap language, research language, cloud documentation, government policy, and market analysis. The article should not flatten those sources into one confidence level. It should explain which source describes live product behavior, which source describes research direction, which source describes policy or funding, and which source describes commercial adoption.
IBM Newsroom sets the first evidence anchor, while IBM Quantum Blog and IBM Quantum provide the cross-check. A workflow reader should ask a concrete question for each source: does this change what we can run today, what we should learn next, what provider route we should test, or what a reviewer must see before the pilot scales?
QFlow can encode that discipline in the product. Source links should not be decorative citations at the bottom of a page. They should become assumptions attached to workflows, route notes, lesson updates, and review packets. When a source is updated or superseded, the affected workflow should be easy to revisit.
Evidence checklist before a pilot scales
Before a pilot based on Quantum-centric supercomputing, Qiskit, HPC scales, QFlow should require a small evidence checklist. The team needs a source brief, a route rationale, an expected artifact list, a fallback path, and a reviewer-safe summary. Without that checklist, 152,064 classical nodes can become an impressive number that nobody can reproduce or defend.
This is especially important when the source trail starts with IBM Newsroom and is supported by IBM Quantum Blog. Those sources may be credible, but the product still has to translate them into accountable workflow state. The article should help the user understand what to inspect next, while the application should preserve the facts that made the decision possible.
A useful evidence packet should include the source date, the claim being tested, the dependency that could break the claim, the human reviewer, and the expected next action if the run fails. That makes the workflow resilient when model access, queue conditions, pricing, hardware availability, or compliance requirements change. The point is not to slow pilots down; it is to make successful pilots repeatable and to make weak pilots fail before they consume more time. It also gives product, research, and operations teams the same language for deciding what ships next.
Workflow implementation path
A practical implementation path should stay small. First, convert the article into one reusable workflow template with a clear objective and a recommended starting route. Second, attach the relevant sources, assumptions, and risk notes to that template. Third, run one dry path and one execution path where provider access allows it. Fourth, generate a reviewer packet that states what worked, what failed, and which assumption deserves the next experiment.
This keeps the article from becoming static content. The writing becomes a product input: it informs templates, route prompts, academy lessons, and admin review rules. The same structure also helps SEO because the page answers the reader's intent directly, then proves the answer through sections, sources, dates, and concrete next actions instead of keyword stuffing.
The implementation path should also protect teams from overcommitting. In 2026, quantum pilots are still sensitive to queue access, backend availability, SDK changes, pricing, and roadmap language. A narrow template lets the team learn quickly while keeping every claim testable.
How QFlow should turn this into workflow design
The interface implication is straightforward: reduce copy-and-paste operations between research, provider consoles, spreadsheets, and review decks. A user reading this article should be able to create or update a workflow with the same assumptions: target modality, run mode, source links, expected outputs, risk notes, and next decision.
That does not require a noisy dashboard. It requires calm hierarchy. The active workflow remains the primary surface, while source context, metrics, route notes, and reviewer artifacts stay close enough to inspect. The result is a product that helps technical users move from analysis to action without losing the audit trail.
The admin surface should reinforce the same model. Editors need long articles that can carry real analysis, but they also need structured fields for sources, metrics, sections, and takeaways so the public page, RSS feed, sitemap, and Open Graph images stay consistent. The content system should therefore support depth without turning every update into a one-off page build. That is how a blog becomes part of the workflow product instead of a detached marketing layer.
Source maintenance and 2026 review cadence
This article should be reviewed whenever a major source changes, a provider updates access, or a market claim becomes stale. A good cadence for 2026 quantum content is monthly for valuation and company articles, quarterly for workflow and education articles, and immediate review for security, standards, and provider availability updates. The review date should be visible so readers understand that the page is maintained.
The maintenance rule is simple: update the article when a source changes the reader's decision. If a new benchmark does not change route selection, evidence requirements, or learning path, it can wait for the next scheduled review. If it changes a run path, procurement stance, or security boundary, the article and the related workflow templates should be updated together.
That cadence follows the practical SEO rule that useful, reliable, current content beats decorative freshness. The page should not be edited just to look active. It should be edited when the source trail, workflow recommendation, or reader action changes.

Next step
Turn this research into a workflow pilot.
Use the same source-to-workflow logic inside the studio: brief, route, run, evidence, and review in one packet.


